














La paraula Deduplicació s’està posant de moda en tots els catàlegs de cabines d’emmagatzematge. S’està convertint en la funcionalitat més buscada. Per molt que els fabricants de discos diguin que el cost per GB és molt baix, la realitat és que l’emmagatzematge segueix sent molt car. Com més es pugui estalviar en ell, millor.
Què és la Deduplicació?
En el meu anterior article, parlo sobre què és i com afecta les nostres màquines la Deduplicació. En resum, un emmagatzematge deduplicat conté una col·lecció de blocs únics i conjunts de metadades que permeten a aquests blocs ser identificats i representats en un sistema informàtic. Aquests blocs són els que componen cadascuna de les nostres VMs (Màquines Virtuals), les quals en gran majoria no són més fitxers de disc.
Les metadades
Simplificant conceptualment, les metadades són una llista de quins blocs únics de dades són els necessaris per construir la VM. En l’emmagatzematge tradicional, cada bloc d’informació de cada VM ocupa un bloc d’espai al disc, fent que aquest contingui moltíssims blocs duplicats que podrien ser optimitzats. Un emmagatzematge deduplicat guarda únicament un bloc únic de cada, reduint considerablement l’espai necessari i brindant als administradors de sistemes molt més espai disponible. Això suposa un estalvi de cost per a l’empresa. I és que, al final, el vostre clúster de VMs són desenes de clons d’una plantilla d’una VM amb un Windows 2012 R2 instal·lat, modificats i adaptats a cadascuna de les funcions dels vostres serveis.

La Deduplicació de Simplivity
SimpliVity crea un sistema de fitxers basat en aquests metadades. Quan la VM fa una escriptura o lectura, el primer que fa és consultar aquesta llista per comprovar si existeix aquest bloc i/o on es troba realment en el disc. Si el bloc existeix, no s’escriu. Només actualitzem les metadades. Si no existeix, llavors l’escriu a l’emmagatzematge.

Normalment, les metadades són un fitxer de text amb una taula de punters als blocs. Per tant, ocupen un espai en disc que varia segons la grandària de dades que representa. Per exemple: un vmdisk d’una VM és un fitxer de 100 GB ple de dades, però que en realitat només ocupen 25 GB en blocs únics i 10 MB en metadades (ull, els números són inventats – no són reals!) Aquesta combinació de blocs únics i les metadades és el que realment necessitem emmagatzemar en els nostres discos per representar un vmdisk en un instant concret de la seva vida.
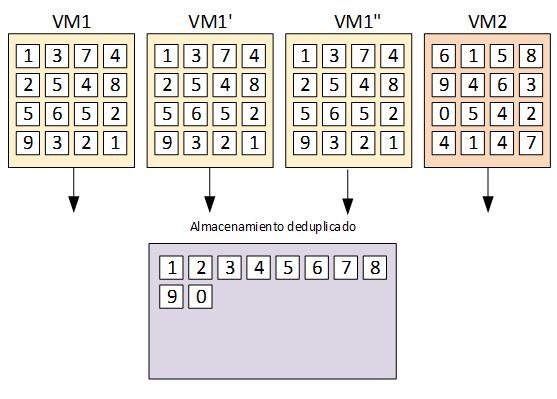
La clonació d’una VM en un emmagatzament deduplicat
En un sistema d’emmagatzematge deduplicat, clonar una VM és tan simple com fer una còpia de les metadades. Aquestes esdevenen punters a blocs de dades úniques que ja han estat emmagatzemades i no hi ha cap necessitat de tornar-los a emmagatzemar. Això vol dir que per fer una còpia de la nostra VM de 100 GB, només cal copiar els 10 MB de metadades, que a més en un node de SimpliVity, estan emmagatzemats en els discos SSD. L’esmentada operació de lectura / escriptura és pràcticament instantània. Amb això, podem realitzar un nombre considerable de clonats de VMs en pocs segons. Per aquest motiu, per a entorns VDI amb creació de màquines, eliminem el tant temut bootstorm a l’inici de la jornada laboral.
A priori pensareu: “no necessito un sistema capaç de clonar una VM 100 per minut i, tret que administri el CPD d’una multinacional amb centenars d’usuaris connectant-se a les seves VDIs a les 8:00, dubto molt que això em sigui rellevant” . Però mirem-ho des d’un altre punt de vista.
Què causa tenir un entorn virtualizat amb 100 VMs?
Tens un entorn virtualitzat amb 100 VMs i no pots fer res més que una còpia sencera de cadascuna d’elles en un horari nocturn. Tot és a causa de les limitacions de les finestres temporals que ens donen als administradors de TI.
I si desitgés fer un backup diverses vegades al dia d’aquestes 100 VMs?
Per a un emmagatzematge deduplicat, un backup i un clonat són exactament el mateix. Per tant, podem fer tants backups del nostre entorn com vulguem. Al final, l’impacte en volum d’emmagatzematge és mínim. A més, l’impacte en el rendiment de les màquines, encara menys!
Això obre un món de possibilitats als administradors de tasques trencant el concepte tradicional de les còpies de seguretat. Ara pots fer còpies dels sistemes de fitxers diverses vegades al dia. Si un usuari comet alguna imprudència (recorda el nociu que aquesta sent CryptoLocker, Ramsonwares, etc.), tens un punt de recuperació molt proper. Així, es minimitza els danys al sistema amb un rollback a tot just minuts abans del desastre. Això et permet restaurar, si vols, un únic arxiu: ¡no tot un VM!.
L’emmagatzament virtual de Simplivity
El més important de la proposta de SimpliVity és que el sistema ha estat dissenyat des de 0 exclusivament per a ser eficient. Per aquest motiu, la Deduplicació s’aplica només quan es realitza l’escriptura de la dada. Totes aquestes tasques amb les metadades (comprovar blocs duplicats, escriptures, lectures, etc,) són absorbides per la Targeta Acceleradora OMNISTACK de SimpliVity. En aquest cas, elimina l’impacte en les VM de producció. Gràcies a un sistema de fitxers ben dissenyat, s’obté tota aquesta “màgia” de SimpliVity.















